[Bria-LoRa-FineTune]
Join our Discord community for more information, tutorials, tools, and to connect with other users!
To use the links below right click on them and open in new tab
The following guide demonstrates Bria best practices for fine tuning on top of our foundation models using Lora architecture and Bria foundation models.
Full implementation of the guide below:
Theory
Dream boot

is a fine-tuning technique designed to personalize generative models like Stable Diffusion. It allows users to train the model on a small set of images (e.g., photos of a person, object, or style) and integrate the learned concept into the model’s vocabulary.
Lora Architecture vs Regular fine tuning
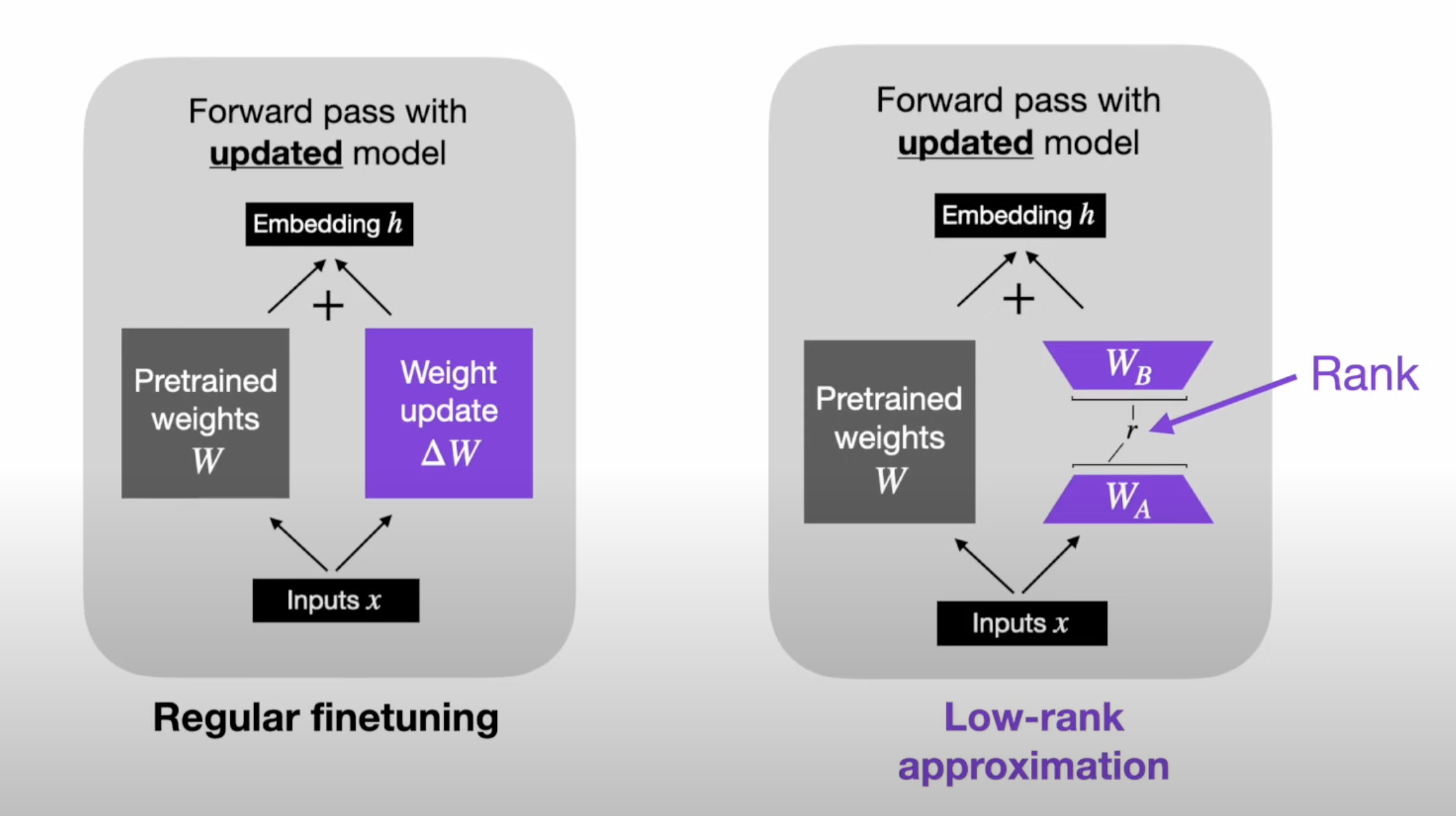
LoRA is a technique to efficiently fine-tune large machine learning models by reducing the number of trainable parameters. Instead of updating the full set of model weights during training, LoRA represents weight updates as the product of two smaller matrices (low-rank matrices).
This approach significantly reduces computational and memory requirements while maintaining high performance, making it particularly useful for large-scale models like transformers. LoRA is widely adopted in applications like NLP and computer vision where fine-tuning massive pre-trained models would otherwise be resource-intensive.
Stochastic Gradient descent
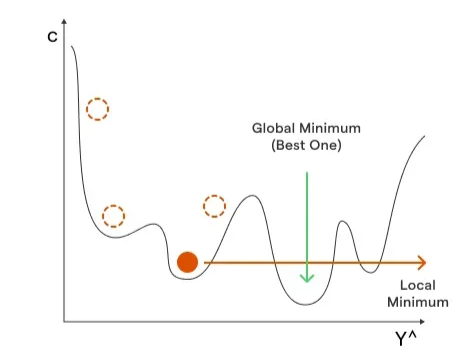
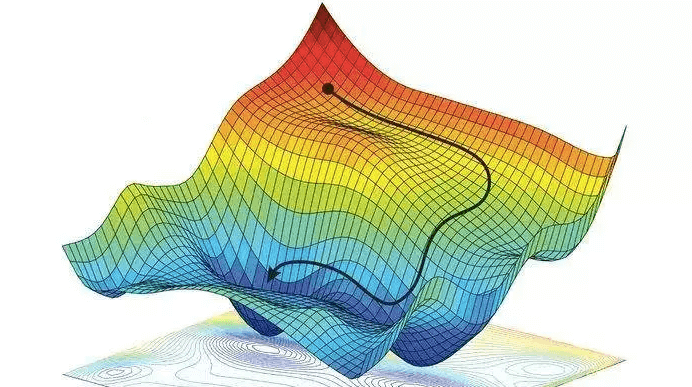
Analogy - Stochastic Gradient Descent (SGD) is like finding the lowest point in a bumpy valley by taking small steps downhill, but instead of looking at the whole valley at once, you only look at one random part of it each time to decide your step.
The diffusion process

Training script
On Bria production we use the standard diffusers code:

But recommend evaluating the more advance methods as well
Recipe
This is the recommended recipe for our auto trading feature:
accelerate launch \
--config_file accelerate_config.yaml \
train_new.py \
--caption_column="..." \
--pretrained_model_name_or_path="briaai/BRIA-2.3" \
--dataset_name=$DATASET_NAME \
--resolution=1024 \
--center_crop \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=1000 \
--checkpointing_steps=200 \
--use_8bit_adam \
--learning_rate=1e-04 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--mixed_precision="bf16" \
--validation_epochs=5 \
--output_dir=$MODEL_DIR \
--rank=16
Model
Use Bria 2.3 as the “go to” model, but if needed our HD can fix quality issues for specific use-cases

Best practices for Tailored Generation training datasets
- For general style we usually use 20-100 images
- For single person / character 10-20
Dataset description
Enhance training performance by providing a concise and clear description of your style or subject.
- Aim to produce results that align with the style of the base model you're training on
- Be brief and accurate and avoid excessive explanations about the style. Instead, use a few, well-chosen words that succinctly capture its essence, either through widely recognized concepts or by directly naming it.
Examples of dataset descriptions:



Style
When training a model for a specific style type, it is crucial to provide images that contain the right information to guide the model. You should use around 20-60 images, and the dataset should consist of a clear style within a specific domain.
The images in your dataset should consider multiple perspectives and the appropriate background styles you aim to create.
Examples of common use cases:
Share the same style:
Datasets can include a wide range of variations as long as they share the same artistic style.



Mixing image styles may lead to poor results.
Ensure your dataset contains images with uniform style, including color schemes and design techniques, to achieve the desired outcomes from the model.



Single subject
When training a model for a single-subject type, it is essential to provide images that include the right information to guide the model. The dataset should contain 10-20 images and should consist of a single subject type, such as a person, car, bottle, animated character, etc.
The images in your dataset should consider multiple perspectives and the appropriate background styles you aim to create.
Here are some examples that demonstrate common use cases:
Multi-Perspective
If you aim for your model to generate images of a single subject from various angles or perspectives, ensure your dataset includes examples showcasing these perspectives.



Incorporating Backgrounds:
Should you desire your model not only to capture the subject but also to learn and replicate the surrounding scenery accurately, it's crucial to include images with backgrounds in your dataset. This approach allows the model to understand how the subject interacts with its environment, enabling it to generate more contextually rich images.



Transparent or solid background:
In cases where the subject is presented against a background of transparent or solid colors (such as white, black, blue, etc.), it is essential to ensure that the subject covers most of the image size. If necessary, it is better to crop the solid margins of the image to reduce the amount of transparency or solid color present.
Consistent image style:
Ensure you don't mix styles within your dataset; for example, a dataset should not contain both animated cars and photo-realistic cars together..



Group of subjects:
If your goal is to generate images featuring your subject in a group, it is advisable to include multiple examples of such groupings in the dataset.



Icons
When training a model for a specific icon style, it is crucial to provide images that contain the right information to guide the model. Users should upload 20-50 images, and the dataset should consist of a clear icons’ style within a specific domain.
The images in your dataset should consider multiple types of icons sharing the same style.
Examples of common use cases:
Share the same style:
Datasets can include a wide range of variations as long as they share the same icons style.



Define the style of the icons in details:
Ensure the description of the icon’s style is as detailed as possible.For example: vector illustration , line art, very thick continuous outlines, minimalistic illustration, vector drawn strokes, continuous strokes


For SVG images, use simple 2D images for training:
To create high-quality images in SVG format, use simple 2D images in your dataset. Images should not include many details, shading, or complex styling.



Captions / Prompts
WIP
Compute
We run on Nvidia A10 GPU:
- On AWS -
g5.xlarge/g5.12xlarge
For any additional questions please contact bar@bria.ai